flowchart LR
Y["Y(t)<br/>Série Observada"] --> T["T(t)<br/>Tendência"]
Y --> S["S(t)<br/>Sazonalidade"]
Y --> C["C(t)<br/>Ciclo"]
Y --> R["R(t)<br/>Resíduo"]
style Y fill:#E50505,color:#fff
style T fill:#3ACC9F,color:#fff
style S fill:#FFCC00,color:#000
style C fill:#F89D49,color:#fff
style R fill:#808080,color:#fff
Aula 1: Fundamentos de Séries Temporais
O que são, por que importam e como descrevê-las
Objetivos de Aprendizagem
- Reconhecer os componentes de uma série temporal (tendência, sazonalidade, ciclo, ruído)
- Interpretar gráficos de autocorrelação (ACF) e autocorrelação parcial (PACF)
- Aplicar métodos de decomposição para separar componentes
- Avaliar se uma série é estacionária usando testes formais
O que é uma Série Temporal?
Uma série temporal é uma sequência de observações indexadas pelo tempo. Diferente de dados cross-section (onde a ordem não importa), em séries temporais a ordem é fundamental — ela carrega informação sobre a dinâmica do fenômeno.
Pense na diferença entre uma planilha de vendas por loja (cross-section) e vendas mensais de uma mesma loja ao longo de 5 anos (série temporal). Na segunda, o mês de dezembro pode sistematicamente vender mais que junho, e uma queda brusca pode indicar uma crise. Essa dependência temporal é o que torna séries temporais especiais — e exige métodos próprios.
Definição Formal
Formalmente, um processo estocástico é uma família indexada de variáveis aleatórias \(\{Y_t\}_{t \in T}\), todas definidas sobre um mesmo espaço de probabilidade \((\Omega, \mathcal{F}, P)\). Cada \(\omega \in \Omega\) determina uma trajetória inteira \(t \mapsto Y_t(\omega)\) - uma “história possível” do processo. Uma série temporal observada é exatamente uma dessas trajetórias.
Quando ajustamos um modelo, tentamos recuperar propriedades do processo (média, covariância, distribuição) a partir de uma única trajetória. Isso só é possível sob hipóteses como estacionariedade e ergodicidade, que veremos adiante.
Onde você encontra séries temporais no trabalho?
- Itaú: preços de ativos, taxa de inadimplência mensal, volume de transações por canal
- JohnDeere: vendas de maquinário por trimestre, preço de commodities agrícolas, demanda sazonal de peças
- Coca-Cola: demanda por SKU e região, temperatura e consumo sazonal, eficácia de campanhas ao longo do tempo
- McKinsey: KPIs de transformação digital ao longo de trimestres, séries de market share, projeções para due diligence
Componentes de uma Série
Toda série temporal pode ser pensada como a combinação de componentes sistemáticos e aleatórios:
| Componente | O que é | Exemplo | Característica |
|---|---|---|---|
| Tendência | Movimento de longo prazo (crescimento ou declínio) | PIB brasileiro crescendo ao longo de décadas | Persistente, suave |
| Sazonalidade | Padrão que se repete em período fixo e conhecido | Vendas de sorvete maiores todo verão | Período constante |
| Ciclo | Flutuações de período variável e desconhecido | Ciclos econômicos de expansão/recessão (3-10 anos) | Menos previsível |
| Resíduo | Variação aleatória após remover os outros componentes | Choques imprevistos (greves, desastres) | Idealmente ruído branco |
NotaTendência vs. Ciclo
Na prática, tendência e ciclo são difíceis de separar. Muitos métodos os tratam juntos como “tendência-ciclo”. A sazonalidade, por ter período fixo, é mais fácil de isolar.
Simulador interativo: Componentes de uma Série Temporal
Use os controles abaixo para construir uma série temporal a partir de seus componentes. Observe como cada um contribui para o formato final.
Decomposição Aditiva vs. Multiplicativa
A forma como os componentes se combinam define o tipo de decomposição:
Aditiva: a amplitude sazonal é constante \[Y_t = T_t + S_t + R_t\]
Multiplicativa: a amplitude sazonal cresce com o nível \[Y_t = T_t \times S_t \times R_t\]
DicaQuando usar cada uma?
Se a amplitude da sazonalidade cresce com o nível da série, use multiplicativa. Se ela permanece constante, use aditiva. Na dúvida, aplique log e use aditiva — pois \(\log(Y_t) = \log(T_t) + \log(S_t) + \log(R_t)\).
Regra prática: plote a série. Se o “zigue-zague” sazonal fica maior quando a série sobe, é multiplicativa.
Simulador: Aditiva vs. Multiplicativa
Compare visualmente as duas formas de decomposição. Na série multiplicativa, observe como a amplitude sazonal cresce com a tendência:
DicaExperimente!
- Com taxa de crescimento alta (0.04–0.05), a diferença fica evidente: na multiplicativa, os picos sazonais ficam cada vez maiores
- Com taxa zero, ambas são idênticas (sem tendência, não há diferença entre aditiva e multiplicativa)
- Na prática, a maioria das séries de vendas e demanda é multiplicativa (sazonalidade proporcional ao nível)
Decomposição Clássica (Médias Móveis)
Antes de métodos mais modernos, a decomposição clássica era o padrão. Ela usa médias móveis para estimar a tendência:
Algoritmo:
- Estimar tendência \(\hat{T}_t\) usando média móvel centrada de ordem \(m\) (onde \(m\) é o período sazonal):
- Para \(m\) ímpar: \(\hat{T}_t = \frac{1}{m}\sum_{j=-(m-1)/2}^{(m-1)/2} Y_{t+j}\)
- Para \(m\) par (ex: \(m=12\)): usa-se média móvel \(2 \times m\) para centralizar
- Remover tendência: calcular \(Y_t - \hat{T}_t\) (aditiva) ou \(Y_t / \hat{T}_t\) (multiplicativa)
- Estimar sazonalidade: fazer a média dos valores desazonalizados para cada período (ex: todos os janeiros, todos os fevereiros…)
- Resíduo: \(\hat{R}_t = Y_t - \hat{T}_t - \hat{S}_t\)
AvisoLimitações da decomposição clássica
- Perde dados nas pontas: a média móvel não produz estimativas para os primeiros e últimos \(m/2\) pontos
- Sazonalidade fixa: assume que o padrão sazonal é constante ao longo do tempo
- Sensível a outliers: um valor extremo afeta toda a média móvel ao redor
- Não é robusta: não tem mecanismo para lidar com mudanças estruturais
Decomposição STL
O método STL (Seasonal and Trend decomposition using Loess) — Cleveland et al. (1990) — resolve todas as limitações da decomposição clássica. É o método recomendado pelo FPP e o que usaremos no curso.
| Característica | Clássica | STL |
|---|---|---|
| Estimação da tendência | Média móvel | Loess (regressão local) |
| Sazonalidade | Fixa no tempo | Pode variar ao longo do tempo |
| Robustez a outliers | Não | Sim (pesos robustos no Loess) |
| Controle de suavização | Nenhum | Parâmetros seasonal e trend |
| Tipo de decomposição | Aditiva ou multiplicativa | Aditiva (usar log para multiplicativa) |
Como funciona o STL (intuição):
- Começa com uma estimativa inicial da tendência (Loess sobre toda a série)
- Remove a tendência e estima a sazonalidade (Loess aplicado a cada subsérie sazonal — todos os janeiros, todos os fevereiros, etc.)
- Remove a sazonalidade e re-estima a tendência
- Repete até convergir (tipicamente 2–3 iterações)
flowchart TD
A["Série Original Y(t)"] --> B["Extrair Tendência<br/>(regressão local: Loess)"]
B --> C["Remover Tendência:<br/>Y(t) - T(t)"]
C --> D["Estimar Sazonalidade<br/>(Loess por subsérie sazonal)"]
D --> E["Resíduo = Y - T - S"]
E --> F{Convergiu?}
F -->|Não| B
F -->|Sim| G["Componentes Finais:<br/>T(t), S(t), R(t)"]
style A fill:#E50505,color:#fff
style G fill:#3ACC9F,color:#fff
Exemplo em Python: Clássica vs. STL
Código
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose, STL
# Criar série exemplo com sazonalidade que muda ao longo do tempo
np.random.seed(42)
n = 144 # 12 anos mensais
t = np.arange(n)
trend = 100 + 0.5 * t
seasonal = 10 * np.sin(2 * np.pi * t / 12) * (1 + 0.01 * t) # sazonalidade crescente
noise = np.random.normal(0, 3, n)
y = trend + seasonal + noise
dates = pd.date_range('2014-01', periods=n, freq='MS')
serie = pd.Series(y, index=dates)
# Decomposição clássica
dec_classica = seasonal_decompose(serie, model='additive', period=12)
# Decomposição STL
dec_stl = STL(serie, period=12, robust=True).fit()
# Comparar
fig, axes = plt.subplots(4, 2, figsize=(14, 10), sharex=True)
fig.suptitle('Decomposição Clássica vs. STL', fontsize=14, fontweight='bold')
for i, (comp, label) in enumerate([
('observed', 'Série Original'),
('trend', 'Tendência'),
('seasonal', 'Sazonalidade'),
('resid', 'Resíduo')
]):
# Clássica
axes[i, 0].plot(getattr(dec_classica, comp), color='#E50505', linewidth=0.8)
axes[i, 0].set_ylabel(label)
if i == 0:
axes[i, 0].set_title('Clássica (Médias Móveis)')
# STL
axes[i, 1].plot(getattr(dec_stl, comp), color='#3ACC9F', linewidth=0.8)
if i == 0:
axes[i, 1].set_title('STL (Loess)')
plt.tight_layout()
plt.show()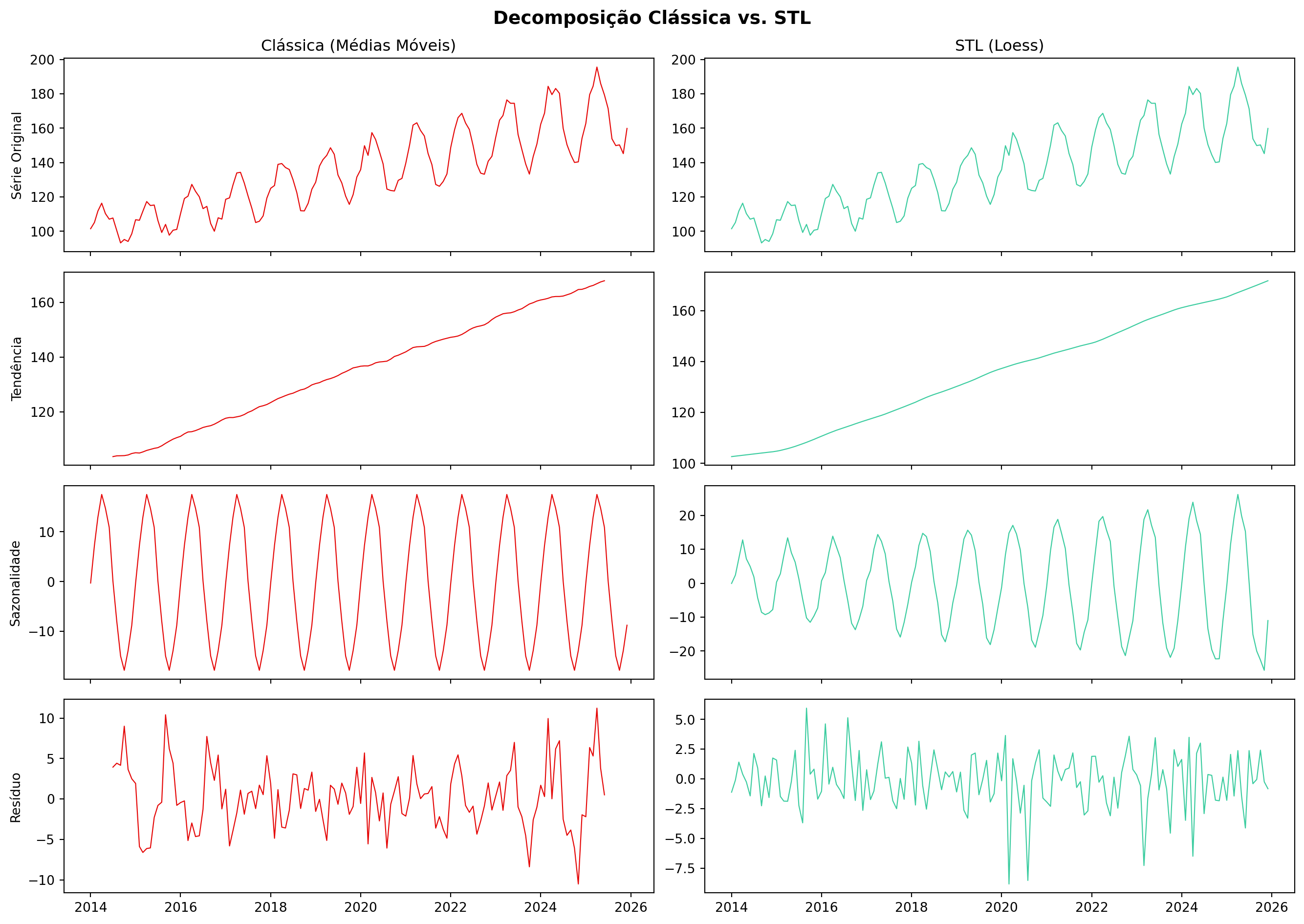
DicaO que observar na comparação
- A tendência STL é mais suave e se estende até as pontas (sem perder dados)
- A sazonalidade STL pode variar ao longo do tempo — note se a amplitude muda
- Os resíduos STL tendem a ser menores e mais “limpos” (menos estrutura remanescente)
- A decomposição clássica tem
NaNnos extremos — dados perdidos pela média móvel
Em Python com statsforecast
O pacote statsforecast da Nixtla também oferece decomposição via MSTL (Multiple Seasonal-Trend decomposition using Loess), que suporta múltiplas sazonalidades simultaneamente:
Código
from statsforecast import StatsForecast
from statsforecast.models import MSTL, AutoARIMA
# MSTL decompõe e depois modela o resíduo com AutoARIMA
models = [MSTL(season_length=12, trend_forecaster=AutoARIMA())]
sf = StatsForecast(models=models, freq='MS')
sf.fit(df=dados) # DataFrame com colunas: unique_id, ds, yAutocorrelação (ACF)
A função de autocorrelação é a ferramenta mais importante na análise descritiva de séries temporais. Ela mede o quanto o valor atual está correlacionado com valores passados.
Autocorrelação no lag \(k\) \[\rho_k = \text{Cor}(Y_t, Y_{t-k}) = \frac{\text{Cov}(Y_t, Y_{t-k})}{\text{Var}(Y_t)}\]
A ideia é simples: se \(\rho_1 = 0.8\), isso significa que o valor de hoje está fortemente correlacionado com o de ontem. Se \(\rho_{12} = 0.6\) em dados mensais, há correlação com o mesmo mês do ano passado (sazonalidade!).
Simulador: ACF de diferentes processos
Escolha um tipo de processo e observe como a ACF se comporta:
Como interpretar a ACF?
| Padrão na ACF | O que indica | Por quê |
|---|---|---|
| Decaimento lento | Série não estacionária (tendência ou raiz unitária) | Valores distantes continuam correlacionados |
| Picos em lags periódicos (12, 24, 36…) | Sazonalidade | Correlação com o mesmo período em anos anteriores |
| Corte abrupto após lag \(q\) | Processo MA(\(q\)) | Apenas \(q\) choques passados importam |
| Decaimento exponencial | Processo AR | Dependência diminui geometricamente |
| Alternância de sinais (+, -, +, -) | AR com coeficiente negativo | Oscilação ao redor da média |
Autocorrelação Parcial (PACF)
A PACF mede a correlação entre \(Y_t\) e \(Y_{t-k}\) após remover o efeito linear de todos os lags intermediários (\(Y_{t-1}, Y_{t-2}, \ldots, Y_{t-k+1}\)).
Em outras palavras: a ACF no lag 3 captura a correlação total entre \(Y_t\) e \(Y_{t-3}\), incluindo a correlação que passa “via” \(Y_{t-1}\) e \(Y_{t-2}\). A PACF no lag 3 captura apenas a correlação direta entre \(Y_t\) e \(Y_{t-3}\).
Como a PACF é calculada?
A PACF no lag \(k\), denotada \(\phi_{kk}\), é o último coeficiente da regressão de \(Y_t\) sobre seus \(k\) valores passados:
\[Y_t = \phi_{k1} Y_{t-1} + \phi_{k2} Y_{t-2} + \cdots + \phi_{kk} Y_{t-k} + \text{erro}\]
O algoritmo mais usado para calculá-la é o Levinson-Durbin, que funciona recursivamente:
- Lag 1: \(\phi_{11} = \rho_1\) (igual à ACF no lag 1)
- Lag 2: \(\phi_{22} = \frac{\rho_2 - \rho_1^2}{1 - \rho_1^2}\)
- Lag \(k\) geral (recursão):
Recursão de Levinson-Durbin \[\phi_{kk} = \frac{\rho_k - \sum_{j=1}^{k-1} \phi_{k-1,j} \cdot \rho_{k-j}}{1 - \sum_{j=1}^{k-1} \phi_{k-1,j} \cdot \rho_j}\]
onde os coeficientes são atualizados por \(\phi_{k,j} = \phi_{k-1,j} - \phi_{kk} \cdot \phi_{k-1,k-j}\).
Intuição: a cada passo, estamos “limpando” a correlação no lag \(k\) de toda a dependência que já foi capturada pelos lags anteriores. Se \(\phi_{kk} \approx 0\), o lag \(k\) não traz informação nova — toda a correlação com \(Y_{t-k}\) era indireta, passando pelos intermediários.
DicaPor que a PACF é tão útil?
Para um AR(\(p\)), a PACF é exatamente zero para todo lag \(> p\). Isso porque, num AR(\(p\)), a dependência de \(Y_t\) com \(Y_{t-k}\) para \(k > p\) é totalmente explicada pelos lags intermediários. A PACF “limpa” essa dependência indireta, deixando apenas a contribuição direta — que é zero.
Regra de Identificação: O “Mapa” ACF/PACF
ImportanteA Tabela de Referência
| Comportamento | ACF | PACF | Modelo sugerido |
|---|---|---|---|
| ACF corta, PACF decai | Corte abrupto em \(q\) | Decaimento exponencial | MA(\(q\)) |
| ACF decai, PACF corta | Decaimento exponencial | Corte abrupto em \(p\) | AR(\(p\)) |
| Ambas decaem | Decaimento exponencial | Decaimento exponencial | ARMA(\(p,q\)) |
| ACF não decai | Decaimento muito lento | Pico no lag 1 | Não estacionário → diferenciar |
Esta tabela é seu principal instrumento de diagnóstico na etapa de identificação.
Observações práticas importantes
AvisoNa prática, o mapa ACF/PACF nem sempre é óbvio!
A tabela acima descreve o comportamento teórico (população infinita). Com dados reais, vários fatores complicam a leitura:
Variabilidade amostral: com amostras finitas, a ACF e PACF têm erro de estimação. Um pico que parece significativo pode ser apenas flutuação aleatória. Use as bandas de confiança (\(\pm 1.96/\sqrt{n}\)) como guia, mas saiba que elas são aproximações.
Decaimento vs. corte nem sempre é nítido: na teoria, a ACF de um AR “decai exponencialmente”. Na prática, o decaimento pode ser tão rápido que parece um corte, ou tão lento que parece não decair. Exige julgamento.
ARMA misturado: quando o processo é ARMA(\(p,q\)) com \(p > 0\) e \(q > 0\), ambas ACF e PACF decaem — e é muito difícil determinar \(p\) e \(q\) visualmente. Nesse caso, critérios de informação (AICc) são mais confiáveis que a inspeção visual.
Fatores sazonais: em dados com sazonalidade (ex: mensais), haverá picos na ACF nos lags 12, 24, 36… Esses picos são a “assinatura” sazonal e devem ser interpretados separadamente da estrutura não-sazonal.
Picos espúrios: ao nível de 5%, esperamos que ~1 em cada 20 lags seja “significativo” por acaso. Se você olha 30 lags, é normal ter 1–2 barras cruzando a linha por acaso.
Recomendação: use a tabela como ponto de partida para gerar hipóteses (candidatos de modelo), não como diagnóstico definitivo. Compare múltiplos candidatos via AICc e diagnóstico residual.
Estacionariedade
O que é estacionariedade?
Uma série é estacionária (no sentido fraco) quando três propriedades são constantes ao longo do tempo:
- Média: \(E[Y_t] = \mu\) para todo \(t\)
- Variância: \(\text{Var}(Y_t) = \sigma^2\) para todo \(t\)
- Autocovariância: \(\text{Cov}(Y_t, Y_{t-k})\) depende apenas de \(k\), não de \(t\)
Em termos práticos: se você “recortasse” qualquer trecho da série, as propriedades estatísticas seriam semelhantes. A série não tem tendência, e sua variabilidade não muda ao longo do tempo.
Por que estacionariedade importa? A maioria dos modelos clássicos (AR, MA, ARMA) assume estacionariedade. Se a série não é estacionária, os estimadores podem ser enviesados e as previsões, absurdas. Por isso, o primeiro passo é sempre verificar e, se necessário, transformar a série para torná-la estacionária.
O que é uma Raiz Unitária?
Este conceito é central e merece explicação cuidadosa.
Considere o modelo AR(1) mais simples possível:
\[Y_t = \phi Y_{t-1} + \varepsilon_t\]
O comportamento da série depende inteiramente do valor de \(\phi\):
Os três regimes do AR(1)
| Condição | Comportamento | Nome |
|---|---|---|
| \(|\phi| < 1\) | Série estacionária — oscila ao redor da média, choques se dissipam | Estável |
| \(\phi = 1\) | Random walk — choques se acumulam para sempre, sem reversão à média | Raiz unitária |
| \(|\phi| > 1\) | Série explosiva — diverge para \(\pm\infty\) rapidamente | Instável |
O caso \(\phi = 1\) é chamado de raiz unitária porque, ao reescrever o AR(1) usando o operador de defasagem \(B\) (onde \(BY_t = Y_{t-1}\)):
\[Y_t = \phi B Y_t + \varepsilon_t \implies (1 - \phi B) Y_t = \varepsilon_t\]
A “raiz” da equação \(1 - \phi z = 0\) é \(z = 1/\phi\). Quando \(\phi = 1\), a raiz está exatamente no círculo unitário (\(z = 1\)), o que torna o processo não estacionário.
NotaTendência Determinística vs. Estocástica
| Tipo | Modelo | Exemplo | Como tratar |
|---|---|---|---|
| Determinística | \(Y_t = \alpha + \beta t + \varepsilon_t\) | Crescimento linear previsível | Incluir tendência no modelo (regressão) |
| Estocástica | \(Y_t = Y_{t-1} + \varepsilon_t\) (random walk) | “Vagueio” aleatório | Diferenciar a série |
A diferença é crucial: se a tendência é determinística, basta incluir \(t\) como variável no modelo. Se é estocástica (raiz unitária), precisamos diferenciar a série. Aplicar o tratamento errado gera resultados enganosos — o famoso problema da regressão espúria.
Testes Formais de Raiz Unitária
| Teste | Hipótese nula (\(H_0\)) | Hipótese alternativa (\(H_1\)) | Interpretação |
|---|---|---|---|
| ADF (Augmented Dickey-Fuller) | Existe raiz unitária (não estacionária) | Série é estacionária | Rejeitar = bom (estacionária) |
| KPSS | Série é estacionária | Existe raiz unitária | Rejeitar = ruim (não estacionária) |
AvisoUse os dois testes juntos!
Os testes têm hipóteses nulas opostas, o que permite uma triangulação:
| ADF | KPSS | Conclusão |
|---|---|---|
| Rejeita \(H_0\) | Não rejeita \(H_0\) | ✅ Evidência de estacionariedade |
| Não rejeita \(H_0\) | Rejeita \(H_0\) | ⚠️ Evidência de raiz unitária — diferenciar |
| Ambos rejeitam | — | ❓ Inconclusivo — pode ser tendência determinística |
| Nenhum rejeita | — | ❓ Inconclusivo — aumente a amostra |
Diferenciação
Se a série tem raiz unitária, aplicamos a diferenciação para torná-la estacionária:
Primeira diferença \[\Delta Y_t = Y_t - Y_{t-1}\]
Diferença sazonal (período \(s\)) \[\Delta_s Y_t = Y_t - Y_{t-s}\]
A primeira diferença remove tendência. A diferença sazonal remove sazonalidade com raiz unitária. Podemos aplicar ambas: \(\Delta \Delta_{12} Y_t\) remove tendência e sazonalidade.
O número de diferenças regulares necessárias será o \(d\) no modelo ARIMA\((p,d,q)\). O número de diferenças sazonais será o \(D\) no SARIMA\((p,d,q)(P,D,Q)_s\).
Quizzes: Teste seu Entendimento
CuidadoQuestão 1: Uma série de vendas mensais mostra picos em dezembro todo ano. Isso é tendência, sazonalidade ou ciclo?
Sazonalidade. Picos que se repetem em período fixo e conhecido (todo dezembro = período de 12 meses) configuram sazonalidade. Se os picos ocorressem a cada 3-7 anos sem período fixo, seria ciclo. Se as vendas estivessem sempre crescendo sem repetição, seria tendência.
CuidadoQuestão 2: Se a ACF decai lentamente e a PACF tem um único pico significativo no lag 1, qual processo isso sugere?
Série não estacionária (provavelmente com raiz unitária). O decaimento lento da ACF é o sinal clássico de não-estacionariedade. A PACF com pico apenas no lag 1 sugere AR(1) com \(\phi\) próximo de 1. A série provavelmente precisa de diferenciação.
Se, após diferenciar, a ACF e a PACF cortam rapidamente, o modelo original é um ARIMA com \(d=1\).
CuidadoQuestão 3: O teste KPSS retornou p-valor = 0.01. O que você conclui?
A série provavelmente NÃO é estacionária. No KPSS, a hipótese nula é que a série é estacionária. Com p-valor = 0.01, rejeitamos \(H_0\) a 5%, o que indica evidência contra estacionariedade.
Mas cuidado: confirme com o ADF. Se o ADF também não rejeitar sua \(H_0\) (raiz unitária), temos evidência robusta de não estacionariedade.
CuidadoQuestão 4: Você aplica uma diferença e a série torna-se estacionária. Qual o valor de \(d\) no ARIMA(p,d,q)?
\(d = 1\), pois foi necessária uma diferenciação regular para atingir estacionariedade. Se precisasse de duas diferenciações, seria \(d = 2\) (raro na prática — \(d > 2\) quase nunca ocorre).
CuidadoQuestão 5: Um colega propôs ajustar um AR(2) diretamente a uma série com tendência crescente. Qual o problema?
O modelo AR assume estacionariedade (média constante). Com tendência, a média está mudando, e o AR vai tentar “perseguir” essa mudança com coeficientes artificialmente altos — os resíduos serão autocorrelacionados e as previsões serão ruins. O correto é: (a) verificar o tipo de tendência (determinística ou estocástica), (b) tratar adequadamente (incluir tendência ou diferenciar), e (c) só então ajustar o modelo AR à série estacionária resultante.
Para Saber Mais
- FPP3, Cap. 2: Time Series Graphics
- FPP3, Cap. 3: Time Series Decomposition
- FPP3, Cap. 9.1: Stationarity and differencing
- Hamilton, J.D. (1994). Time Series Analysis, Cap. 15 — Unit Roots.