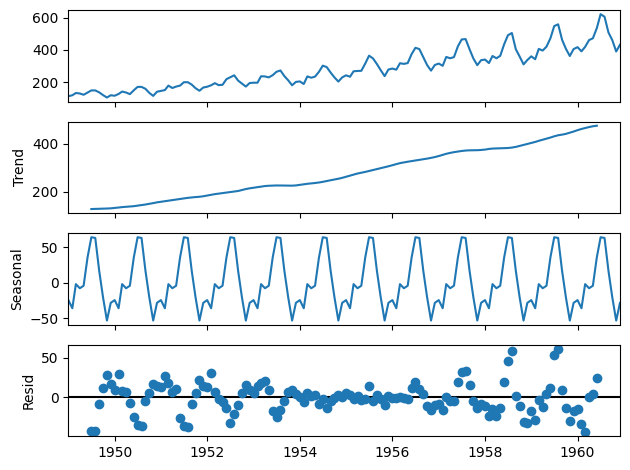
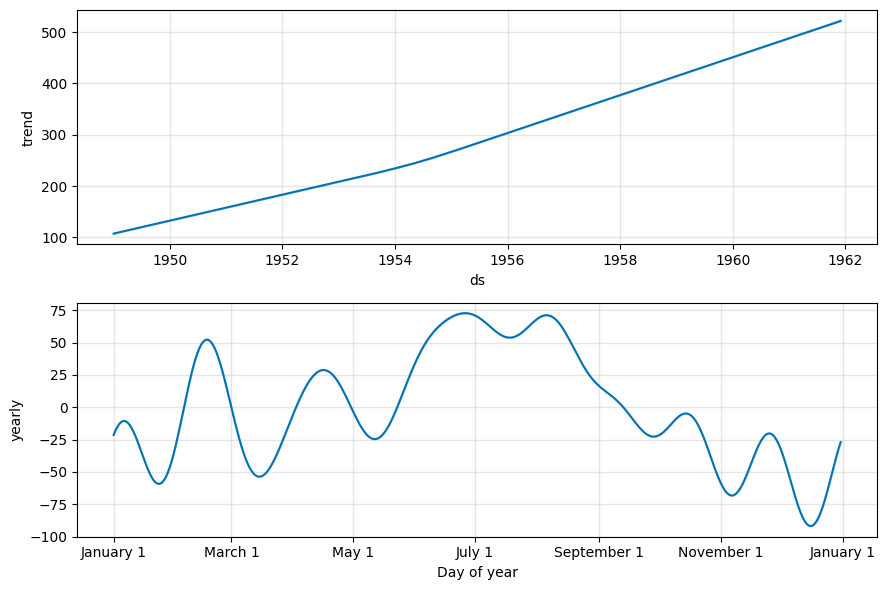
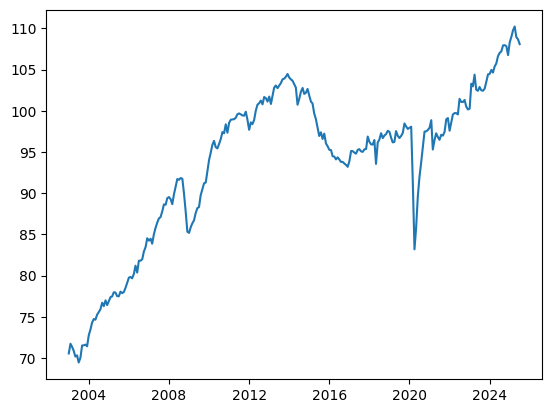
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
from scipy.stats import norm
# 1. Geração de Dados (Usando scipy.stats.norm)
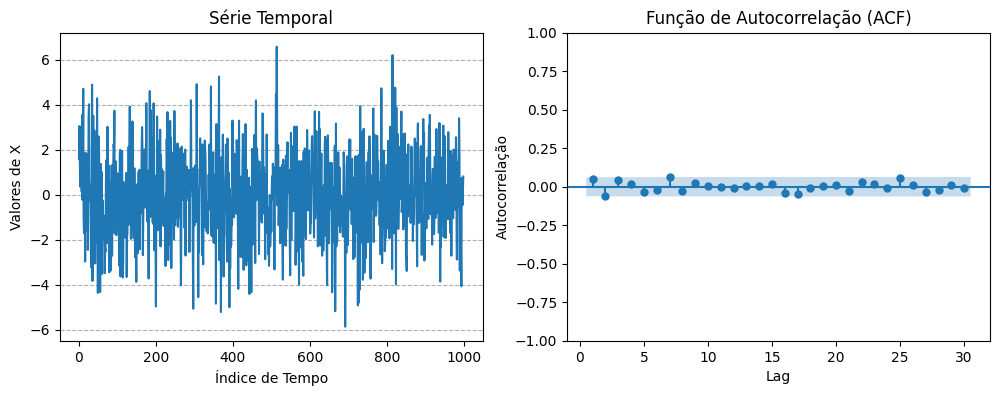
X = norm.rvs(loc=0, scale=2, size=1000)
# 2. Configuração do Layout do Gráfico (1 linha, 2 colunas)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 3. Plotagem da Série Temporal
axes[0].plot(X)
axes[0].set_title('Série Temporal')
axes[0].set_xlabel('Índice de Tempo')
axes[0].set_ylabel('Valores de X')
axes[0].grid(axis='y', linestyle='--')
# 4. Plotagem da ACF (Função de Autocorrelação)
plot_acf(X,
ax=axes[1],
title='Função de Autocorrelação (ACF)',
zero=False)
axes[1].set_xlabel('Lag')
axes[1].set_ylabel('Autocorrelação')